
Oğuz Gürerk*
1980’li yıllara kadar Türkiye’de kamuoyu araştırmalarının kurumsal olarak ve düzenli aralıklarla yapıldığı pek söylenemez. Medya kuruluşları 1983 Milletvekili genel Seçimleri ile kamuoyu araştırmalarını maddi olarak desteklemeye ve yayın organlarında bu araştırmalara geniş yerler ayırmaya başlamalarıyla birlikte kamuoyu yoklamaları seçim periyotlarında daha Evvel görülmemiş ölçüde gündelik hayatın kesimi olmuş ve giderek yaygınlaşmıştır. öbür taraftan, hatırlayabildiğim kadarıyla, Türkiye’de evvelki seçimlerde bugün olduğu kadar “anketlerin anketi” yahut “seçim simülasyonları” üzere meraklar yoktu, Aka olasılıkla ABD’den Türkiye’deki seçim ortamını incelemek için ithal edilmiş (ve oy Eda pratiğini giderek bir mühendislik sorunu üzere gösteren) yeni “alışkanlıklar”la karşı karşıyayız.
Bu yazıda seçim (ya da muhayyel bir meclisteki vekil dağılımlarının) simülasyonlarını değil, genel olarak anket birleştirmeleriyle ilgili birkaç Kıymetli noktaya dikkat çekmek isterim. 2018 Cumhurbaşkanlığı (CB) ve 2019 Mahallî Seçimlerinde seçime bir ay kala seçim anketi yayımlayan şirketlerin bir “isabetlilik” endeksinin nasıl çıkartılabileceğini ve bunu kullanarak 14 Mayıs’a yönelik nasıl bir “anket birleştirme” [poll aggregation] yapılabileceğini anlamak için başvurabileceğimiz kimi araçlar var. Bunlardan biri de şirketlerin geçmiş seçimlerdeki kusur oranlarını ortak ve seçimden seçime değişmeyen bir ölçüte nazaran kıymetlendirerek her bir şirketin genel olarak ne kadar “isabetli” olduğunun bir endeksinin kullanışlılığını da görmeye çalışmaktır. Bunun için rastgele bir şirketin bir seçim öncesi yaptığı nihayet anket ilgili seçim sonucuyla ne kadar örtüşüyorsa o anketi yapan şirketin, birleştirmedeki rölâtif tartısının o kadar Çok olması gerektiği öncülünden devinim edeceğiz.
Anket birleştirme, gayeye ait daha emniyetli bir öngörü elde etmek üzere makul bir bahis yahut seçimle ilgili apansızın Çok anket sonucunu bir ortaya getiren bir tekniktir; anketlerin Yalın ortalamasını alarak yahut anketleri birleştirirken Türlü Bayes modelleri, yumuşatma [smoothing] algoritmaları veya (anketleri ortaya çıkarttığı varsayılan) kuramsal bir Vakit serisi sürecinin istatistiksel modellemesi üzere karmaşık teknikler kullanılarak yapılabilir. Bu formüllerin hepsini başka başlıklar halinde tanımlayıp tartışabiliriz fakat atılan taşın ürkütülen kurbağaya değip değmeyeceği başka bir soru işareti.
Anket birleştirme uygulaması, farklı anketlerin tasarım ve örneklem büyüklüğündeki farklılıklarının hesaba katılmasıyla kuramsal olarak Yekün kusur hissesini azaltabilir ve öngörünün isabetliliğini arttırabilir. Fakat ne yazık ki ilgili bilgilere erişilebilirlik ve güvenirlilik problemleri Türkiye’de birçok Vakit aşılamayan zorluklardır. İrem Aydaş (2020) yüksek lisans tezinde 2011-2019 yılları ortasında Türkiye’deki 11 seçim periyodundan 374 seçim öncesi anketinin raporlama uygulamalarını inceleyerek çarpıcı gerçeği ortaya çıkarmıştır: bütün bu anketlerin yaklaşık %69’u, örnekleme prosedürü belirtilmeden bildirilmiştir[2]. Metodolojik şeffaflığın olmaması bu anketlerin geçerliliğini tehlikeye atmaktadır. Anketler, örnekleme hatalarının[3] ötesinde, ekseriyetle raporlanan yanılgı hisselerinde ihmal edilen çerçevelendirme [framing], ölçüm [measurement] ve belirlenim [specification] yanılgılarından da muzdariptir. Ayrıyeten şirketlerin belli örnekleme kalıpları, şeffaf olmayan yüklendirme formülleri yahut siyasi bağlantılarına/bağlılıklarına atfedilebilecek eğilimleri de suları bulandırmaktadır.
Dolayısıyla seçmenlerin yani “kamuoyunun” siyasi ruh halindeki gerçek değişimleri kamuoyu yoklamalarındaki mümkün tarafgirlikten ayırmak pek kolay değil. Önerdiğimiz anket birleştirme usulü, Martin ve öbürleri (2005) tarafından ortaya konulan bir isabetlilik ölçütü kullanarak anket şirketlerinin geçmiş performanslarına dayalı olarak Türkiye’deki seçim öncesi anketlerini kıymetlendirmektedir – doğal, tarafsız ve kaliteli bir anketin taraflı, kalitesiz sonuçların bir ortaya getirilmesinden birçok Vakit daha başarılı olacağını unutmadan.
Bu nedenle sırf Noksan bildirilmiş anketlerle hudutlu olmayarak rastgele bir anket birleştirme sistemi (veya yenilenen anket bilgilerinin istatistiksel modellemesi), savunulacağı bilimsel temelden mahrumdur. Bununla birlikte, Fazla sayıda seçim öncesi anketini, kullanacağımız ölçüte nazaran “isabetlilik”leri temelinde incelemek, anket şirketlerine mahsus eğilimlerin ve/veya siyasi bağlılıklarının nitekim olup olmadığını anlamamıza Yardımcı olabilir. Akabinde bir anketin isabetliliği ne kadar yüksekse, ilgili şirketin birleştirmede o kadar Çok tartısı hak ettiği önermesine dayanan anket birleştirme örneğimize geçeceğiz.
Şimdi kelamını ettiğimiz, Martin ve başkalarına (2005) nazaran, bir anketin taraflılığının ölçüsünün matematiksel temsilini “A” ile gösterelim. Bu ölçü, bir anketin iki partili bir seçimin sonucunu kestirim etmede ne kadar isabetli olduğunu nicelleştirmeyi sağlayacak. Aşağıda R/D sırasıyla Cumhuriyetçiler ve Demokratlar için seçimdeki gerçek oy oranı ve r/d muhakkak bir seçim anketindeki iki parti için dayanak oranıdır.
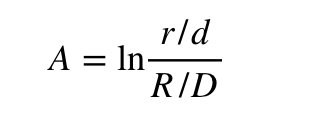
A ölçüsü, bu iki oranın oranının doğal logaritmasıdır; ilgili anketin iki parti ortasındaki oy oranı varsayımını, gerçek oy oranıyla karşılaştırır. Şayet anket sonucu seçim sonucuyla büsbütün örtüşüyorsa, r/d ile R/D kıymetleri eşit olacak ve A sıfır olacaktır. Şayet anket, kazanan partinin oy oranını seçim sonucundakine nazaran daha Çok bulduysa r/d, R/D‘den daha Aka olacak ve A müspet olacaktır. Aksine, anket, kazanan partinin oy oranını seçim sonucuna nazaran daha düşük bulduysa r/d, R/D‘den daha Ufak olacak ve A negatif olacaktır. Hasebiyle, A ölçüsü, bir anketin eğilimini [bias] nicelleştirmenin bir yoludur ve sıfıra ne kadar yakınsa, anket o kadar eğilimsiz ve başarılı olur[4].
Bununla birlikte, Özgün haliyle A sırf iki partili sistemler için Müsait olduğundan Arzheimer ve Evans (2014) bu metodu ikiden Çok partinin olduğu Fazla partili seçimlere uygulanabilir hale getirerek genelleştirmiştir, bu yeni ölçütü olarak göstereceğiz – burada daha Çok matematiksel detaya yer vermeden meraklı okuyucuyu ilgili makalelere yönlendirmek isterim. Tablo 1’de 2018 CB seçimine en Çok 1 ay kala yapılan seçim anketlerinin ortalama kusur hisselerine nazaran sıralamasını görüyoruz, bir anket için değeri tabloda Namzet bazındaki bedellerin (yani adaylara ait eğilimlerin) mutlak bedellerinin ortalamasıdır ve 0’a ne kadar yakınsa ilgili şirketin seçim anketinin gerçek seçim sonucuyla o kadar düzgün örtüştüğünü belirtir. Tablo 2, Tablo 1’deki anket sonuçlarının tarihlerine nazaran sıralanmış halidir ve bedellerinin hesaplandığı yayımlanmış sonuçları içerir.
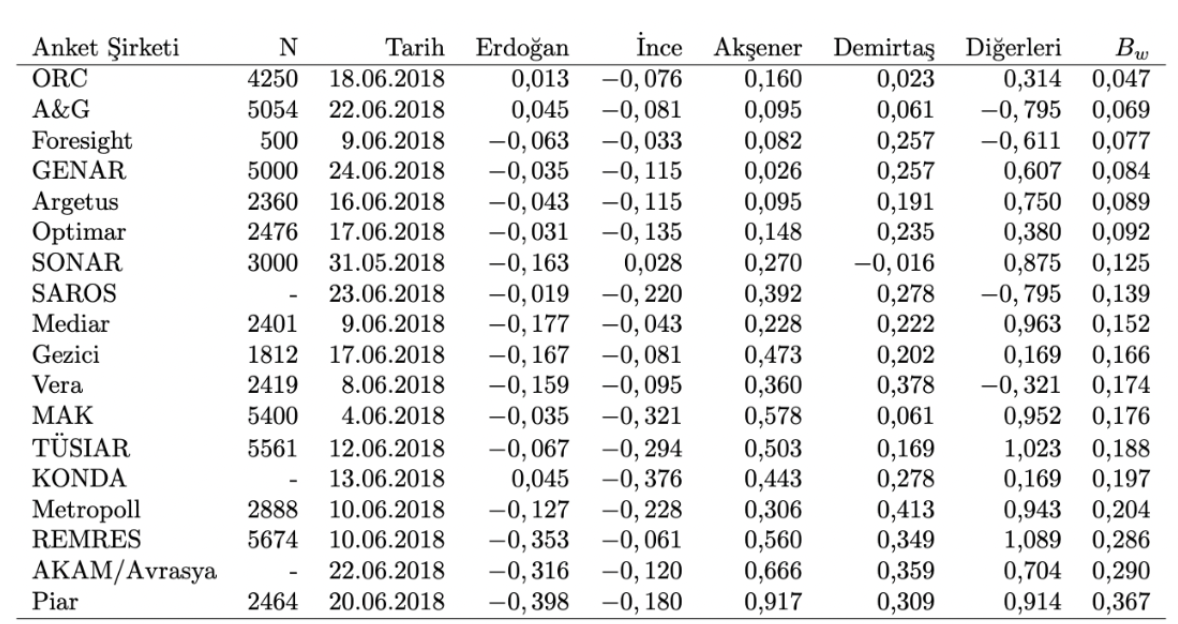
Tablo 1
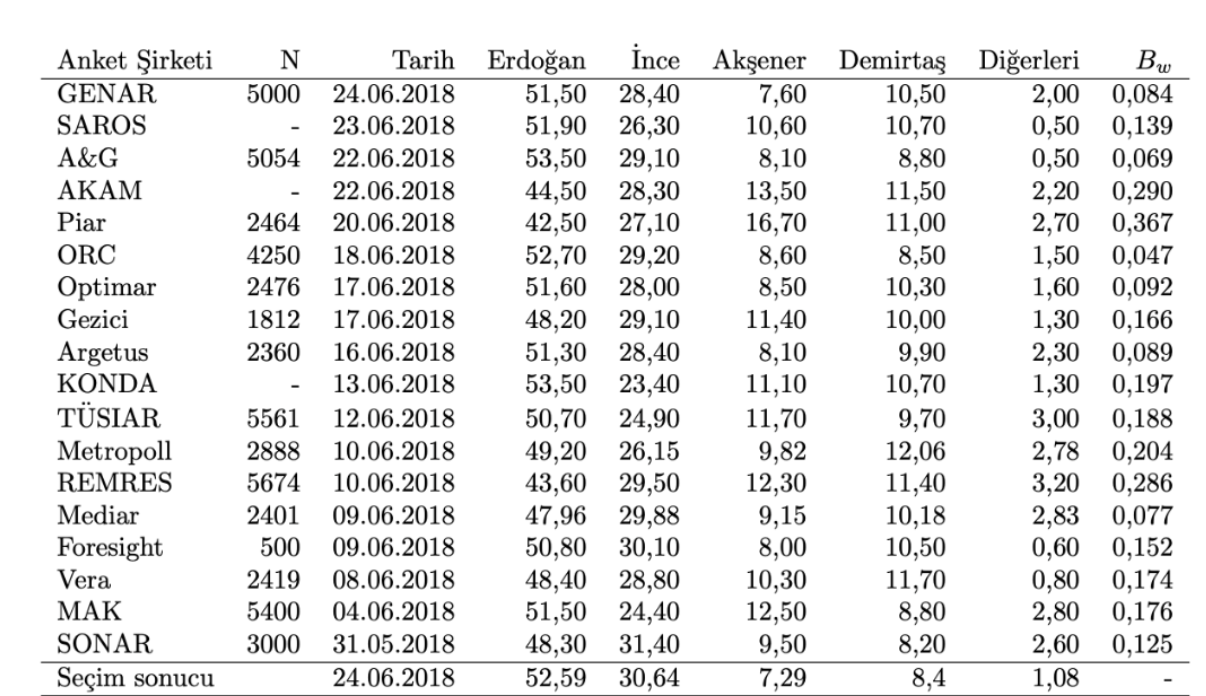
Tablo 2
Anket firmalarının 2019 Belediye Seçimlerindeki performanslarını ( ölçütüne dayalı olarak) 2018 Cumhurbaşkanlığı seçimlerinden elde edilen skorlarla birleştirerek önümüzdeki CB seçimi için Sonuç “paylaşan” anket şirketlerinin ortalama yüklerini hesaplıyoruz, böylelikle şirketlerin evvelki başarılarına nazaran ağırlıklandırılmış bir anket birleştirme grafiği çizebiliyoruz.
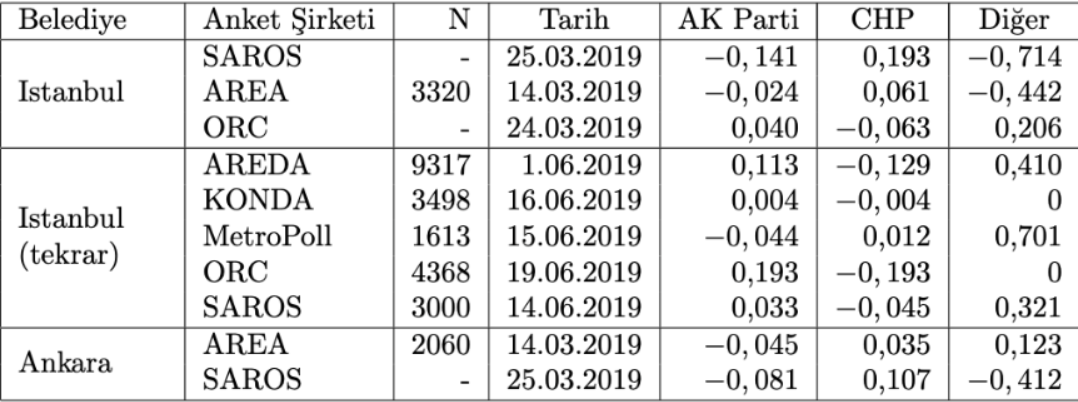
Tablo 3: Belediye seçimlerinde Sonuç açıklamış anket şirketleri için Namzet bazında eğilimler.
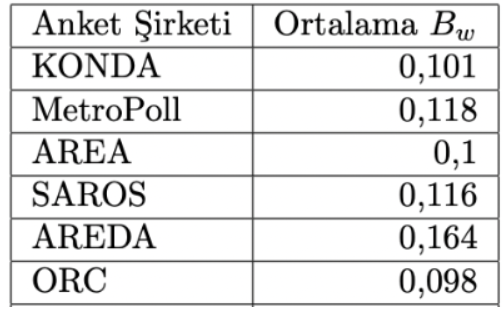
Tablo 4: 2018 CB ve 2019 Lokal Seçimlerine nazaran ortalama Bw değerleri.
Eğer bir anket şirketi görece yeniyse, yani daha Evvel hiçbir seçim için ölçümü yoksa, o Vakit bu şirkete (seçeceğimiz) alt kümedeki şirketlerden en düşük skora sahip olan şirketin skoru kadar tartı veriyoruz, böylelikle bu şirketi yalnızca yeni olduğu için cezalandırmamış oluyoruz. nihayet olarak bu fikrin hareketteki haline göz atalım.
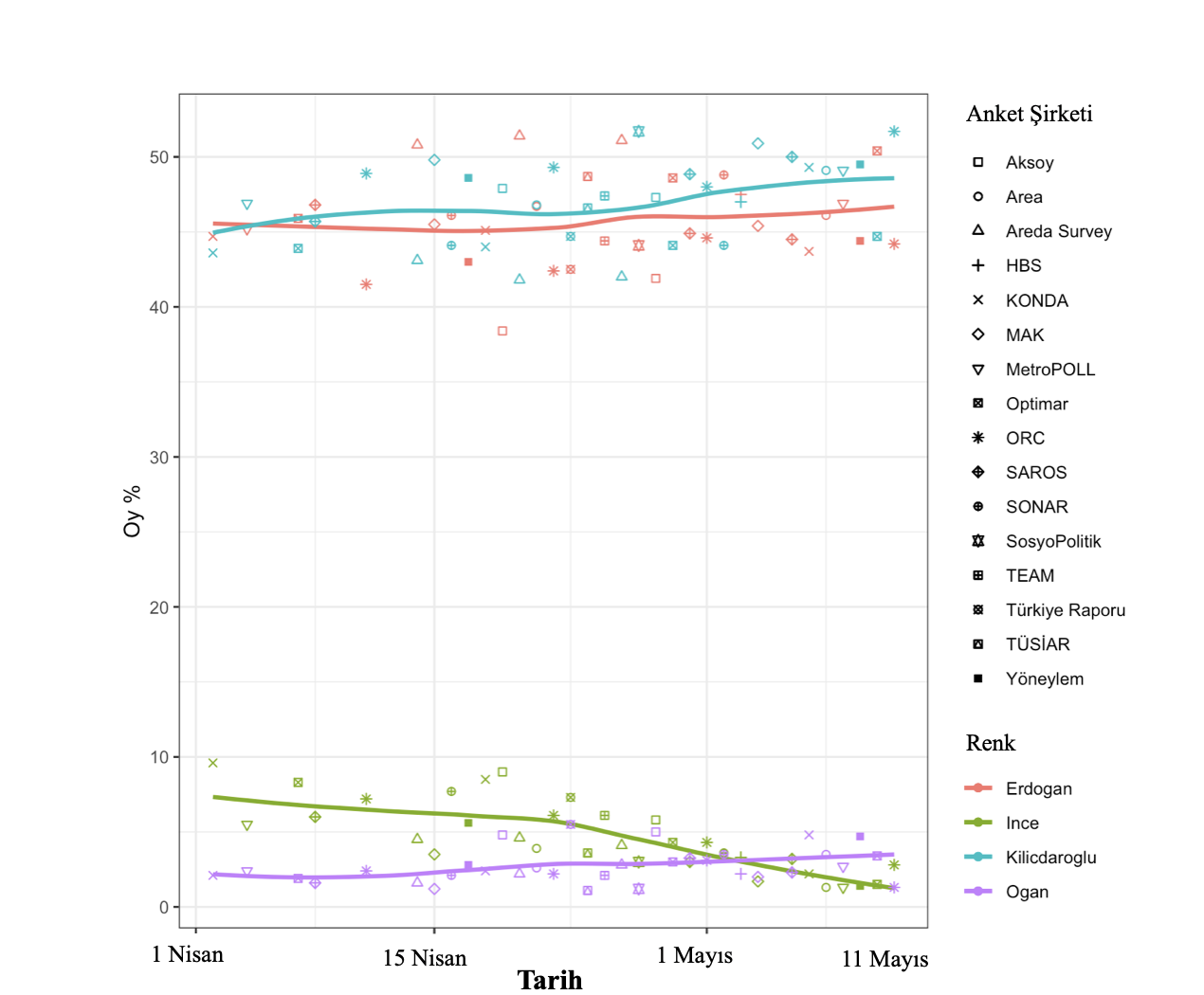
Yukarıdaki örnekte sıralanmış şirketlerin en nihayet 12 Mayıs saat 13.00’a kadar yayımlamış olduğu seçim anketlerini içeren anket birleştirme örneğini görüyoruz[5]. Bu birleştirmeye en nihayet eklenen iki anket sonucu dikkate paha; biri Optimar’ın, Öteki ORC’nin: İkisi de neredeyse tıpkı Vakit aralığında[6] yapılmış ve ikisinin de genel müdürleri tarafından paylaşılan hesaplarda anketlerin yüzde 95 itimat aralığında 1,8 kusur hissesine sahip olduğu belirtiliyor ve iki anket de seçmen nüfusunu temsil ettiğini tez ediyor.
Dolayısıyla karşı karşıya kaldığımız durum, bir evvelki yazıda Tanım ettiğim çelişkili anket sonuçlarının epeyce benzerini teşkil ediyor ve yani biliyoruz ki bu iki sonuçtan en az biri çok(!) Aka bir olasılıkla ya nihayet derece yanlışlı ya da taraflı… Artık bu ikisinden birini, diyelim ki Optimar’ınkini iç etmeyeceğiz, o Vakit – öteki her şeyi sabit tutarsak – karşımıza çıkacak olan grafik aşağıdaki olacaktı. En sondaki birleştirmede de Optimar’ı tutup ORC’yi çıkartıyoruz ve buna nazaran çiziyoruz. Bu grafiklerden hangisinin gerçeklikle daha Çok örtüşeceğini yarın öğreneceğiz.
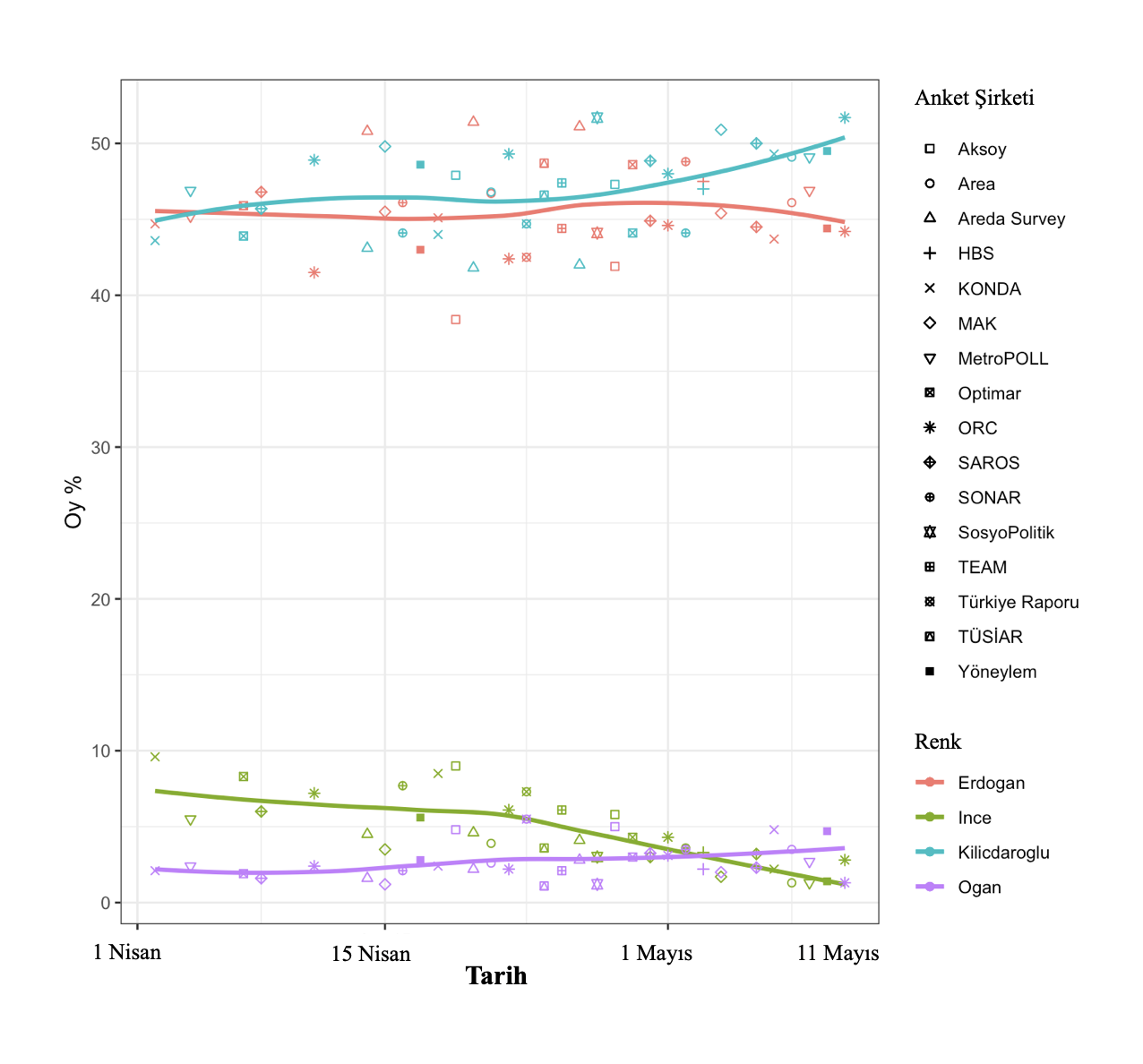
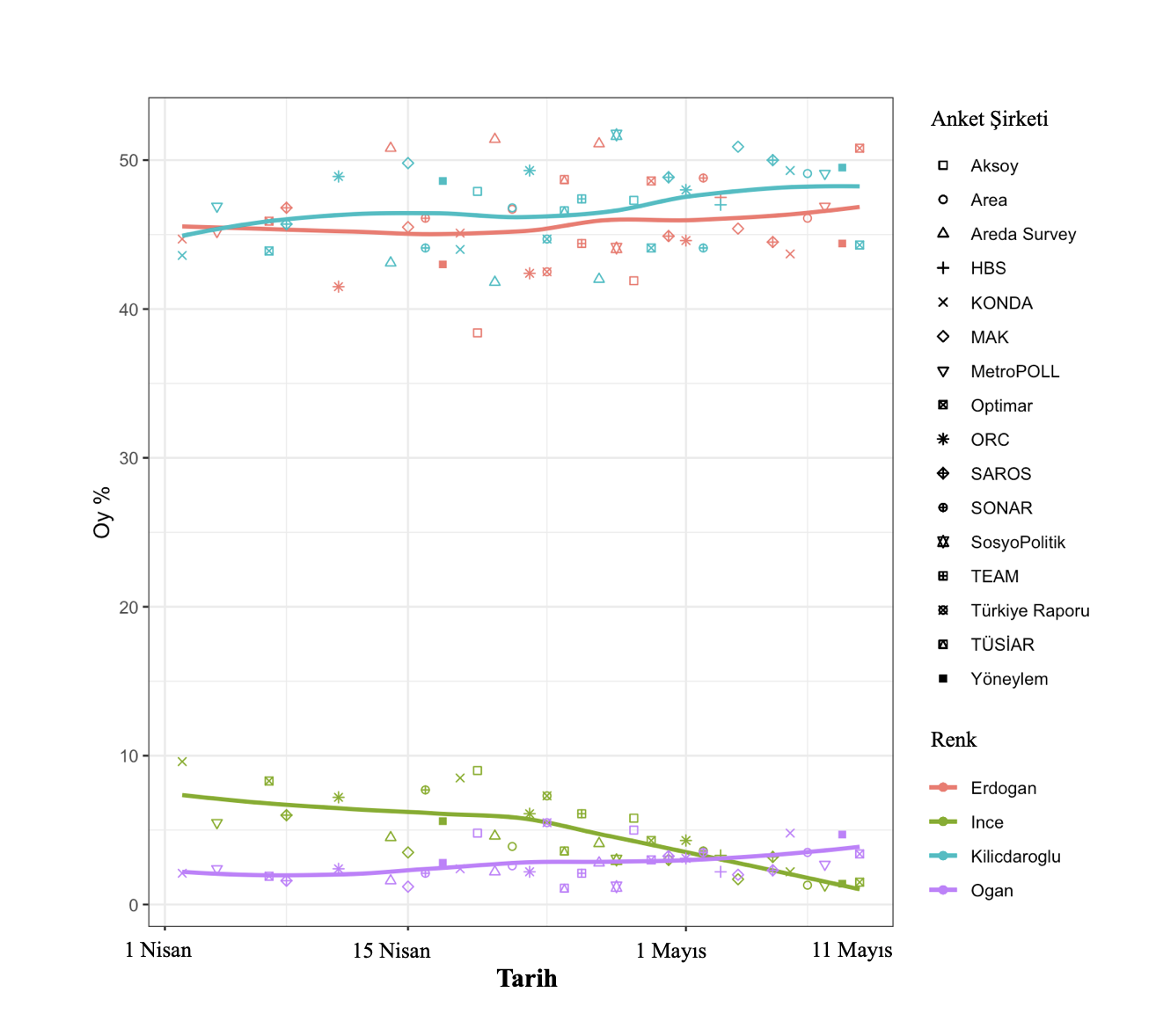
* Oğuz Gürerk, Boğaziçi Üniversitesi’nde matematik ve İktisat okudu. alaka ve çalışma alanlarının başında metodoloji (nitel, nicel, bilişimsel) geliyor, Koç Üniversitesi Hesaplamalı Toplumsal Bilimler Merkezi’nde Politus ERC Projesi kapsamında Politus Analytics (https://politusanalytics.com/) data platformunun oluşturulması amacıyla araştırmacı olarak çalışmaktadır.
[1] Bir evvelki yazma aslında bu yazının birinci halinden daha sonra yazıldı. Evvelki yazıyı doğuran muhtaçlık, Çeşitli şirketlerin nüfusu temsil tezindeki anket sonuçlarının birbirlerinden – neredeyse çelişki oluşturacak kadar – farklı olmalarının ne kadar Muhtemel olduğunu anlamaya çalışmaktı. Bunun için önümüzdeki CB Seçimine yönelik iki hayali anket sonucunu istatistiksel bir “oyuncak-model” ile kıyaslamıştım: “Kamuoyu kimin oyu yahut kamuoyu yoklamalarına nereye kadar güvenebiliriz?”, T24 (9 Mayıs 2023), https://t24.com.tr/haber/kamuoyu-kimin-oyu-veya-kamuoyu-yoklamalarina-nereye-kadar-guvenebiliriz,1108414.
[2] İrem Aydaş, Pre-election polls in Turkey, yayımlanmamış yüksek lisans tezi, Sabancı Üniversitesi, 2020.
[3] genel olarak Aka örneklemli anketler – öbür her şey sabit tutulduğunda – Ufak örneklemli anketlerden daha isabetli sonuçlar üretir zira daha Aka bir örneklem, daha Ufak bir kusur hissesine İmkan sağlar; bu da sonuçların, incelenen nüfusu temsil etme kabiliyetinin daha yüksek olduğu manasına gelir. Lakin, örnekleme yanılgısının [sampling error] bilakis, örneklemeden Müstakil kusurlar basitçe daha Çok ve daha Aka anketler yapılarak azaltılamaz. Yanılgı hissesinin, örneklemin rastgele oluşturulduğu varsayımına dayalı olarak hesaplanan bir örneklem kestirimindeki [sample estimate] belirsizlik seviyesini [level of uncertainty] belirtmek için kullanılan istatistiksel bir kavram olduğunu unutmayalım. Örneklem rastgele örneklemeyle oluşturulmadıysa, yanılgı hissesi, ilgili kestirimle alakalı belirsizliğin geçerli bir ölçüsü değildir ve bu durumda kusur hissesini bildirmek aldatıcı olur – maalesef Türkiye’de birçok anket bundan da muzdariptir. Bu nedenle örneklemin ve onu oluşturmak için kullanılan yolun sınırlamalarını bilmek Fazla kıymetlidir.
[4] Bu ölçünün kullanışlılığı çarçabuk hesaplanabilir ve özetlenebilir olmasından da geliyor; Martin ve başkalarının (2005) anketlerin isabetliliğini ölçmek için kullanılan evvelki metotlardan neden daha üstün olduğunu tartıştığı makale için: Elizabeth A. Martin, Michael W. Traugott, and Courtney Kennedy, A review and proposal for a new measure of poll accuracy, The Public Opinion Quarterly, 69(3):342–369, 2005. Bu ölçütün seçim iddialarına tesir eden eğilimlerin tabiatı ve kapsamı hakkında Fazla değişkenli istatistiksel tahlillerde bağımlı değişken olarak kullanılabilir ve bu eğilimlerin mümkün kaynaklarını belirlemeye Yardımcı olabilir. Farklı seçimlerde ve kararsız seçmenlerin sayısında yahut kararsızların ele alınmasında farklılık gösteren anketler ortasında karşılaştırılabilir. Daha Çok detay ve İzah için: Kai Arzheimer and Jocelyn Evans, A new multinomial accuracy measure for polling bias, Political Analysis, 22(1):31–44, 2014.
[5] Ayrıntılar için benim de araştırmacı olarak içinde bulunduğum Politus Analytics’in raporuna bakınız: https://politusanalytics.com/wp-content/uploads/2023/05/Politus-Turkiye-Panoramasi-1.pdf
[6] Optimar’ın ilgili anketi 9-11 Mayıs tarihleri ortasında yaptığı, ORC’nin ise 10-11 Mayıs ortasında gerçekleştirdiği belirtiliyor.




Yorum Yok